Buchstabenhäufigkeit
| Buchstabe | Relative Häufigkeit in der englischen Sprache ⓘ | |||
|---|---|---|---|---|
| Texte | Wörterbücher | |||
| A | 8.2% | 7.8% | ||
| B | 1.5% | 2% | ||
| C | 2.8% | 4% | ||
| D | 4.3% | 3.8% | ||
| E | 13% | 11% | ||
| F | 2.2% | 1.4% | ||
| G | 2% | 3% | ||
| H | 6.1% | 2.3% | ||
| I | 7% | 8.6% | ||
| J | 0.15% | 0.21% | ||
| K | 0.77% | 0.97% | ||
| L | 4% | 5.3% | ||
| M | 2.4% | 2.7% | ||
| N | 6.7% | 7.2% | ||
| O | 7.5% | 6.1% | ||
| P | 1.9% | 2.8% | ||
| Q | 0.095% | 0.19% | ||
| R | 6% | 7.3% | ||
| S | 6.3% | 8.7% | ||
| T | 9.1% | 6.7% | ||
| U | 2.8% | 3.3% | ||
| V | 0.98% | 1% | ||
| W | 2.4% | 0.91% | ||
| X | 0.15% | 0.27% | ||
| Y | 2% | 1.6% | ||
| Z | 0.074% | 0.44% | ||
Die Buchstabenhäufigkeit ist die Anzahl der Buchstaben des Alphabets, die im Durchschnitt in der geschriebenen Sprache vorkommen. Die Buchstabenhäufigkeitsanalyse geht auf den arabischen Mathematiker Al-Kindi (ca. 801-873 n. Chr.) zurück, der die Methode zum Brechen von Chiffren formell entwickelte. In Europa gewann die Buchstabenhäufigkeitsanalyse mit der Entwicklung der beweglichen Lettern um 1450 n. Chr. an Bedeutung, da man die für jede Buchstabenform benötigte Schriftmenge abschätzen musste. Sprachwissenschaftler verwenden die Buchstabenhäufigkeitsanalyse als rudimentäre Technik zur Identifizierung von Sprachen, wobei sie besonders effektiv ist, wenn es darum geht, festzustellen, ob ein unbekanntes Schriftsystem alphabetisch, syllabisch oder ideographisch ist. ⓘ
Die Verwendung von Buchstabenhäufigkeiten und Häufigkeitsanalysen spielt eine grundlegende Rolle bei Kryptogrammen und verschiedenen Worträtselspielen, darunter Hangman, Scrabble, Wordle und die Fernsehspielshow Wheel of Fortune. Eine der frühesten Beschreibungen in der klassischen Literatur, in der die Kenntnis der englischen Buchstabenhäufigkeit zur Lösung eines Kryptogramms angewandt wird, findet sich in Edgar Allan Poes berühmter Geschichte Der Goldkäfer, in der die Methode erfolgreich zur Entschlüsselung einer Nachricht angewandt wird, die den Standort eines von Kapitän Kidd versteckten Schatzes angibt. ⓘ
Herbert S. Zim gibt in seinem klassischen kryptographischen Einführungstext "Codes and Secret Writing" die Häufigkeitsfolge der englischen Buchstaben als "ETAON RISHD LFCMU GYPWB VKJXZQ" an, die häufigsten Buchstabenpaare als "TH HE AN RE ER IN ON AT ND ST ES EN OF TE ED OR TI HI AS TO" und die häufigsten verdoppelten Buchstaben als "LL EE SS OO TT FF RR NN PP CC". Unterschiedliche Zählweisen können zu etwas unterschiedlichen Reihenfolgen führen. ⓘ
Die Buchstabenhäufigkeit hat auch einen starken Einfluss auf die Gestaltung einiger Tastaturlayouts. Die häufigsten Buchstaben befinden sich in der unteren Zeile der Blickensderfer-Schreibmaschine und in der ersten Zeile der Dvorak-Tastatur. ⓘ
Die Buchstabenhäufigkeit (Graphemhäufigkeit) ist eine statistische Größe, die angibt, wie oft ein bestimmter Buchstabe in einem Text oder einer Sammlung von Texten (Korpus) vorkommt. Sie kann als absolute Anzahl oder in Relation zur Gesamtzahl der Buchstaben des Textes angegeben werden. Die Häufigkeitsverteilung der Buchstaben hängt von der jeweiligen Sprache ab. Während frühere Annahmen pauschal die statistische Verteilung der Buchstabenhäufigkeit durch das Zipfsche Gesetz vorherzusagen glaubten, hat die quantitative Linguistik gezeigt, dass eine Reihe anderer Wahrscheinlichkeitsverteilungen in Betracht zu ziehen sind. Zählungen zur Häufigkeit von Buchstaben oder Lauten in Texten oder Textkorpora sind spätestens seit dem frühen 19. Jahrhundert nachweisbar. Für manche Zwecke ist es auch interessant, wie häufig ein Buchstabe am Wortanfang oder am Wortende vorkommt. ⓘ
Hintergrund

Die Häufigkeit von Buchstaben in Texten wurde für die Kryptoanalyse und insbesondere für die Häufigkeitsanalyse untersucht, die auf den arabischen Mathematiker Al-Kindi (ca. 801-873 n. Chr.) zurückgeht, der die Methode formell entwickelte (die mit dieser Technik zu knackenden Chiffren gehen mindestens auf die von Julius Cäsar erfundene Caesar-Chiffre zurück, so dass diese Methode bereits in der Antike erforscht worden sein könnte). Die Analyse der Buchstabenhäufigkeit gewann in Europa mit der Entwicklung der beweglichen Lettern um 1450 n. Chr. zusätzlich an Bedeutung, da man die für jede Buchstabenform benötigte Menge an Schrift abschätzen muss, was sich an den unterschiedlichen Größen der Buchstabenfächer in den Setzkästen der Typografen ablesen lässt. ⓘ
Es gibt keine exakte Verteilung der Buchstabenhäufigkeit in einer bestimmten Sprache, da jeder Schreiber etwas anders schreibt. Die meisten Sprachen weisen jedoch eine charakteristische Verteilung auf, die in längeren Texten deutlich erkennbar ist. Selbst bei so extremen Sprachwechseln wie dem vom Altenglischen zum modernen Englisch (das als unverständlich gilt) zeigen sich starke Tendenzen bei den entsprechenden Buchstabenhäufigkeiten: In einer kleinen Stichprobe von Bibelstellen, von der häufigsten zur seltensten, steht enaid sorhm tgþlwu æcfy ðbpxz im Altenglischen im Vergleich zu eotha sinrd luymw fgcbp kvjqxz im modernen Englisch, wobei die extremsten Unterschiede bei den Buchstabenformen nicht geteilt werden. ⓘ
Die Linotype-Maschinen für die englische Sprache übernahmen die Reihenfolge der Buchstaben vom häufigsten zum seltensten, etaoin shrdlu cmfwyp vbgkjq xz, basierend auf der Erfahrung und den Gewohnheiten der manuellen Setzer. Die Entsprechung für die französische Sprache war elaoin sdrétu cmfhyp vbgwqj xz. ⓘ
Ordnet man das Morsealphabet in Gruppen von Buchstaben an, die gleich viel Zeit für die Übertragung benötigen, und sortiert diese Gruppen dann in aufsteigender Reihenfolge, so ergibt sich e it san hurdm wgvlfbk opxcz jyq. Die Buchstabenfrequenz wurde auch von anderen Telegrafiesystemen wie dem Murray-Code verwendet. ⓘ
Ähnliche Ideen werden in modernen Datenkomprimierungstechniken wie der Huffman-Kodierung verwendet. ⓘ
Die Buchstabenhäufigkeit ist wie die Worthäufigkeit von Autor zu Autor und von Thema zu Thema unterschiedlich. Man kann keinen Aufsatz über Röntgenstrahlen schreiben, ohne häufige X zu verwenden, und der Aufsatz wird eine eigenwillige Buchstabenhäufigkeit haben, wenn es um die Verwendung von Röntgenstrahlen zur Behandlung von Zebras in Katar geht. Verschiedene Autoren haben Gewohnheiten, die sich in der Verwendung von Buchstaben widerspiegeln können. Hemingways Schreibstil unterscheidet sich zum Beispiel deutlich von dem Faulkners. Buchstaben, Bigramme, Trigramme, Worthäufigkeiten, Wortlängen und Satzlängen können für bestimmte Autoren berechnet werden und dazu dienen, die Urheberschaft von Texten zu beweisen oder zu widerlegen, auch für Autoren, deren Stile nicht so unterschiedlich sind. ⓘ
Genaue durchschnittliche Buchstabenhäufigkeiten können nur durch die Analyse einer großen Menge repräsentativer Texte ermittelt werden. Mit der Verfügbarkeit moderner Computer und Sammlungen großer Textkorpora lassen sich solche Berechnungen leicht durchführen. Beispiele können aus einer Vielzahl von Quellen (Presseberichterstattung, religiöse Texte, wissenschaftliche Texte und allgemeine Belletristik) entnommen werden, und insbesondere in der allgemeinen Belletristik gibt es Unterschiede bei der Stellung von "h" und "i", wobei das "h" häufiger wird. ⓘ
Außerdem ist zu beachten, dass sich unterschiedliche Dialekte einer Sprache auch auf die Häufigkeit eines Buchstabens auswirken. So würde beispielsweise ein Autor in den Vereinigten Staaten etwas verfassen, in dem der Buchstabe "z" häufiger vorkommt als ein Autor im Vereinigten Königreich, der über dasselbe Thema schreibt: Wörter wie "analyze", "apologize" und "recognize" enthalten den Buchstaben im amerikanischen Englisch, während die gleichen Wörter im britischen Englisch "analyse", "apologise" und "recognise" geschrieben werden. Dies würde die Häufigkeit des Buchstabens "z" stark beeinflussen, da dieser Buchstabe von britischen Sprechern in der englischen Sprache nur selten verwendet wird. ⓘ
Die zwölf wichtigsten Buchstaben machen etwa 80 % der gesamten Verwendung aus. Die "ersten acht" Buchstaben machen etwa 65 % der gesamten Verwendung aus. Die Buchstabenhäufigkeit als Funktion des Ranges lässt sich durch verschiedene Rangfunktionen gut anpassen, wobei die zweiparametrige Cocho/Beta-Rangfunktion die beste ist. Eine andere Rangfunktion ohne einstellbare freie Parameter passt sich ebenfalls recht gut an die Buchstabenhäufigkeitsverteilung an (dieselbe Funktion wurde auch zur Anpassung der Aminosäurehäufigkeit in Proteinsequenzen verwendet). Ein Spion, der die VIC-Chiffre oder eine andere Chiffre auf der Grundlage eines übergreifenden Schachbretts verwendet, benutzt in der Regel eine Eselsbrücke wie "a sin to err" (unter Weglassung des zweiten "r") oder "at one sir", um sich die ersten acht Buchstaben zu merken. ⓘ
Die Buchstabenhäufigkeit wird in der Entschlüsselung von Substitutionsverfahren in der Kryptoanalyse sowie in der Datenkompression und -kodierung benutzt. Bei einfachen Verschlüsselungsverfahren wie bei der Cäsarchiffre kann ein Geheimtext alleine durch Häufigkeitsanalyse entschlüsselt werden. Dabei werden die Häufigkeiten der einzelnen Zeichen im Geheimtext festgestellt und dann mit der Häufigkeit der Zeichen in einem Klartext der vermuteten Sprache verglichen. Nun werden die Buchstaben des Geheimtextes durch die normalen Buchstaben gleicher Häufigkeit ersetzt. Der häufigste Buchstabe des Geheimtextes entspricht dann zum Beispiel dem Klartextbuchstaben e. Diese Methode ist offensichtlich für längere zu entschlüsselnde Texte besonders gut geeignet, weil die statistische Abweichung der gefundenen Buchstabenhäufigkeit von der zu erwartenden Häufigkeit geringer wird. ⓘ
Für den Maschinenschreibunterricht ist es wichtig, dass die Lehrkraft über die Buchstabenhäufigkeit in einer Sprache gut informiert ist und die Unterrichtsinhalte entsprechend darauf abgestimmt werden. Häufige Buchstaben wie das E oder das I müssen hinreichend trainiert werden, um eine möglichst hohe Anschlagszahl und eine gute Schreibsicherheit zu erzielen. Bei der Erstellung ergonomischer Tastaturbelegungen spielt die Buchstabenhäufigkeit ebenfalls eine große Rolle. Hersteller von Buchstabenspielen wie Boggle oder Scrabble berücksichtigen bei den nationalen Varianten ebenfalls die Häufigkeit und, falls vorhanden, auch die Wertigkeit der Buchstaben. ⓘ
Eine der ersten Anwendungen war das Morse-Alphabet, das für häufige Zeichen kurze Codes verwendet (zum Beispiel E = ·); für selten gebrauchte Zeichen dagegen längere Codes (zum Beispiel Q = – – · –). ⓘ
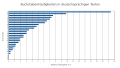
Diagramm zu der relativen Buchstabenhäufigkeit in deutschsprachigen Texten

Monogramm-Häufigkeitsgebirge: Die Buchstaben-Häufigkeitsverteilung eines längeren deutschen Textes.
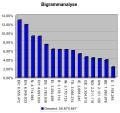
Bigramm-Häufigkeitsgebirge: Verteilung der häufigsten Bigramme in einem deutschen Text.

Trigramm-Häufigkeitsgebirge: Verteilung der häufigsten Trigramme in einem deutschen Text. Die Tripel ER_ und EN_ sind am häufigsten [_ steht für das Leerzeichen].
3D Säulendiagramm: Häufigkeit der Vokalbuchstaben in serbokroatischen Texten

3D Säulendiagramm: Häufigkeit der Konsonantenbuchstaben in serbokroatischen Texten ⓘ






Relative Häufigkeit der Buchstaben in der englischen Sprache

Es gibt drei Möglichkeiten, die Buchstabenhäufigkeit zu zählen, die zu sehr unterschiedlichen Diagrammen für gängige Buchstaben führen. Die erste Methode, die in der folgenden Tabelle verwendet wird, besteht darin, die Buchstabenhäufigkeit in den Stammwörtern eines Wörterbuchs zu zählen. Bei der zweiten Methode werden alle Wortvarianten mitgezählt, z. B. "abstrakt", "abstrahiert" und "abstrahieren", und nicht nur der Wortstamm von "abstrakt". Dieses System führt dazu, dass Buchstaben wie "s" viel häufiger vorkommen, z. B. beim Zählen von Buchstaben aus Listen der am häufigsten verwendeten englischen Wörter im Internet. Eine letzte Variante ist die Zählung von Buchstaben auf der Grundlage ihrer Verwendungshäufigkeit in tatsächlichen Texten, was dazu führt, dass bestimmte Buchstabenkombinationen wie "th" aufgrund der häufigen Verwendung gängiger Wörter wie "der", "dann", "beide", "dies" usw. häufiger vorkommen. Absolute Verwendungshäufigkeiten wie diese werden bei der Erstellung von Tastaturlayouts oder Buchstabenhäufigkeiten in altmodischen Druckmaschinen verwendet. ⓘ
Eine Analyse der Einträge im Concise Oxford Dictionary, bei der die Häufigkeit der Wortverwendung nicht berücksichtigt wird, ergibt die Reihenfolge "EARIOTNSLCUDPMHGBFYWKVXZJQ". ⓘ
Die nachstehende Tabelle der Buchstabenhäufigkeit stammt von der Website von Pavel Mička, der sich auf Robert Lewands Kryptologische Mathematik beruft. ⓘ
Nach Lewand lauten die Buchstaben in der Reihenfolge ihres häufigsten Auftretens: etaoinshrdlcumwfgypbvkjxqz. Lewands Anordnung unterscheidet sich geringfügig von anderen, wie dem Cornell University Math Explorer's Project, das nach der Messung von 40.000 Wörtern eine Tabelle erstellt hat. ⓘ
Im Englischen ist das Leerzeichen etwas häufiger als der Anfangsbuchstabe (e), und die nicht-alphabetischen Zeichen (Ziffern, Satzzeichen usw.) stehen gemeinsam an vierter Stelle (nachdem das Leerzeichen bereits enthalten ist) zwischen t und a. ⓘ
Relative Häufigkeit der Anfangsbuchstaben eines Wortes in der englischen Sprache
| Buchstabe | Relative Häufigkeit des ersten Buchstabens eines englischen Wortes ⓘ | |||
|---|---|---|---|---|
| Texte | Wörterbücher | |||
| A | 11.7% | 5.7% | ||
| B | 4.4% | 6% | ||
| C | 5.2% | 9.4% | ||
| D | 3.2% | 6.1% | ||
| E | 2.8% | 3.9% | ||
| F | 4% | 4.1% | ||
| G | 1.6% | 3.3% | ||
| H | 4.2% | 3.7% | ||
| I | 7.3% | 3.9% | ||
| J | 0.51% | 1.1% | ||
| K | 0.86% | 1% | ||
| L | 2.4% | 3.1% | ||
| M | 3.8% | 5.6% | ||
| N | 2.3% | 2.2% | ||
| O | 7.6% | 2.5% | ||
| P | 4.3% | 7.7% | ||
| Q | 0.22% | 0.49% | ||
| R | 2.8% | 6% | ||
| S | 6.7% | 11% | ||
| T | 16% | 5% | ||
| U | 1.2% | 2.9% | ||
| V | 0.82% | 1.5% | ||
| W | 5.5% | 2.7% | ||
| X | 0.045% | 0.05% | ||
| Y | 0.76% | 0.36% | ||
| Z | 0.045% | 0.24% | ||
Die Häufigkeit der Anfangsbuchstaben von Wörtern oder Namen ist hilfreich bei der Vorabzuweisung von Platz in physischen Akten und Registern. Bei 26 Schubladen eines Aktenschranks wäre eine Zuordnung von 1: 1 Zuordnung einer Schublade zu einem Buchstaben des Alphabets, ist es oft sinnvoll, einen Buchstabencode mit gleichmäßigerer Häufigkeit zu verwenden, indem man mehrere Buchstaben mit niedriger Häufigkeit derselben Schublade zuordnet (oft wird eine Schublade mit VWXYZ bezeichnet) und die häufigsten Anfangsbuchstaben ("S", "A" und "C") auf mehrere Schubladen aufteilt (oft 6 Schubladen Aa-An, Ao-Az, Ca-Cj, Ck-Cz, Sa-Si, Sj-Sz). Dasselbe System wird in einigen mehrbändigen Werken wie z. B. einigen Enzyklopädien verwendet. In einigen Bibliotheken werden Cutter-Nummern verwendet, eine weitere Zuordnung von Namen zu einem Code mit gleichmäßigerer Häufigkeit. ⓘ
Sowohl die Gesamtverteilung der Buchstaben als auch die Verteilung der Wortanfangsbuchstaben entsprechen in etwa der Zipf-Verteilung und sogar noch besser der Yule-Verteilung. ⓘ
Oft weicht die Häufigkeitsverteilung der ersten Ziffer in jedem Datenwert erheblich von der Gesamthäufigkeit aller Ziffern in einem numerischen Datensatz ab, siehe Benfordsches Gesetz für Details. ⓘ
In einer Analyse von Peter Norvig zu Google Books-Daten wurde unter anderem die Häufigkeit der Anfangsbuchstaben englischer Wörter ermittelt. ⓘ
Eine Analyse vom Juni 2012, bei der ein Textdokument verwendet wurde, das alle Wörter der englischen Sprache genau einmal enthält, ergab, dass "S" der häufigste Anfangsbuchstabe für Wörter in der englischen Sprache ist, gefolgt von "P", "C" und "A". ⓘ
Die Häufigkeit von Anfangsbuchstaben gibt an, wie oft ein Buchstabe als erster Buchstabe eines Wortes vorkommt. Sie hängt relativ stark von der Textart ab. Für Fließtext sind die fünf häufigsten Anfangsbuchstaben:
| Platz | Buchstabe | Relative Häufigkeit ⓘ |
|---|---|---|
| 1. | D | 14,2 % |
| 2. | S | 10,8 % |
| 3. | E | 7,8 % |
| 4. | I | 7,1 % |
| 5. | W | 6,8 % |
Für Lexika ergibt sich eine andere Verteilung. Die Buchstaben D, E, I und W kommen im Vergleich zum Fließtext wesentlich seltener am Wortanfang vor, S kommt mit deutlichem Abstand am häufigsten vor:
| Platz | Buchstabe | Relative Häufigkeit ⓘ |
|---|---|---|
| 1. | S | 11,8 % |
| 2. | K | 7,3 % |
| 3. | A | 7,1 % |
| 4. | P | 7,0 % |
| 5. | B | 5,7 % |
| 6. | M | 5,7 % |
Relative Häufigkeit von Buchstaben in anderen Sprachen
| Buchstabe | Englisch | Französisch | Deutsch | Spanisch | Portugiesisch | Esperanto | Italienisch | Türkisch | Schwedisch | Polnisch | Niederländisch | Dänisch | Isländisch | Finnisch | Tschechisch ⓘ |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| a | 8.167% | 7.636% | 6.516% | 11.525% | 14.634% | 12.117% | 11.745% | 11.920% | 9.383% | 8.910% | 7.486% | 6.025% | 10.110% | 12.217% | 8.421% |
| b | 1.492% | 0.901% | 1.886% | 2.215% | 1.043% | 0.980% | 0.927% | 2.844% | 1.535% | 1.470% | 1.584% | 2.000% | 1.043% | 0.281% | 0.822% |
| c | 2.782% | 3.260% | 2.732% | 4.019% | 3.882% | 0.776% | 4.501% | 0.963% | 1.486% | 3.960% | 1.242% | 0.565% | ~0% | 0.281% | 0.740% |
| d | 4.253% | 3.669% | 5.076% | 5.010% | 4.992% | 3.044% | 3.736% | 4.706% | 4.702% | 3.250% | 5.933% | 5.858% | 1.575% | 1.043% | 3.475% |
| e | 12.702% | 14.715% | 16.396% | 12.181% | 12.570% | 8.995% | 11.792% | 8.912% | 10.149% | 7.660% | 18.91% | 15.453% | 6.418% | 7.968% | 7.562% |
| f | 2.228% | 1.066% | 1.656% | 0.692% | 1.023% | 1.037% | 1.153% | 0.461% | 2.027% | 0.300% | 0.805% | 2.406% | 3.013% | 0.194% | 0.084% |
| g | 2.015% | 0.866% | 3.009% | 1.768% | 1.303% | 1.171% | 1.644% | 1.253% | 2.862% | 1.420% | 3.403% | 4.077% | 4.241% | 0.392% | 0.092% |
| h | 6.094% | 0.737% | 4.577% | 0.703% | 0.781% | 0.384% | 0.636% | 1.212% | 2.090% | 1.080% | 2.380% | 1.621% | 1.871% | 1.851% | 1.356% |
| i | 6.966% | 7.529% | 6.550% | 6.247% | 6.186% | 10.012% | 10.143% | 8.600%* | 5.817% | 8.210% | 6.499% | 6.000% | 7.578% | 10.817% | 6.073% |
| j | 0.153% | 0.613% | 0.268% | 0.493% | 0.397% | 3.501% | 0.011% | 0.034% | 0.614% | 2.280% | 1.46% | 0.730% | 1.144% | 2.042% | 1.433% |
| k | 0.772% | 0.074% | 1.417% | 0.011% | 0.015% | 4.163% | 0.009% | 4.683% | 3.140% | 3.510% | 2.248% | 3.395% | 3.314% | 4.973% | 2.894% |
| l | 4.025% | 5.456% | 3.437% | 4.967% | 2.779% | 6.104% | 6.510% | 5.922% | 5.275% | 2.100% | 3.568% | 5.229% | 4.532% | 5.761% | 3.802% |
| m | 2.406% | 2.968% | 2.534% | 3.157% | 4.738% | 2.994% | 2.512% | 3.752% | 3.471% | 2.800% | 2.213% | 3.237% | 4.041% | 3.202% | 2.446% |
| n | 6.749% | 7.095% | 9.776% | 6.712% | 4.446% | 7.955% | 6.883% | 7.487% | 8.542% | 5.520% | 10.032% | 7.240% | 7.711% | 8.826% | 6.468% |
| o | 7.507% | 5.796% | 2.594% | 8.683% | 9.735% | 8.779% | 9.832% | 2.476% | 4.482% | 7.750% | 6.063% | 4.636% | 2.166% | 5.614% | 6.695% |
| p | 1.929% | 2.521% | 0.670% | 2.510% | 2.523% | 2.755% | 3.056% | 0.886% | 1.839% | 3.130% | 1.57% | 1.756% | 0.789% | 1.842% | 1.906% |
| q | 0.095% | 1.362% | 0.018% | 0.877% | 1.204% | 0 | 0.505% | 0 | 0.020% | 0.140% | 0.009% | 0.007% | 0 | 0.013% | 0.001% |
| r | 5.987% | 6.693% | 7.003% | 6.871% | 6.530% | 5.914% | 6.367% | 6.722% | 8.431% | 4.690% | 6.411% | 8.956% | 8.581% | 2.872% | 4.799% |
| s | 6.327% | 7.948% | 7.270% | 7.977% | 6.805% | 6.092% | 4.981% | 3.014% | 6.590% | 4.320% | 3.73% | 5.805% | 5.630% | 7.862% | 5.212% |
| t | 9.056% | 7.244% | 6.154% | 4.632% | 4.336% | 5.276% | 5.623% | 3.314% | 7.691% | 3.980% | 6.79% | 6.862% | 4.953% | 8.750% | 5.727% |
| u | 2.758% | 6.311% | 4.166% | 2.927% | 3.639% | 3.183% | 3.011% | 3.235% | 1.919% | 2.500% | 1.99% | 1.979% | 4.562% | 5.008% | 2.160% |
| v | 0.978% | 1.838% | 0.846% | 1.138% | 1.575% | 1.904% | 2.097% | 0.959% | 2.415% | 0.040% | 2.85% | 2.332% | 2.437% | 2.250% | 5.344% |
| w | 2.360% | 0.049% | 1.921% | 0.017% | 0.037% | 0 | 0.033% | 0 | 0.142% | 4.650% | 1.52% | 0.069% | 0 | 0.094% | 0.016% |
| x | 0.150% | 0.427% | 0.034% | 0.215% | 0.253% | 0 | 0.003% | 0 | 0.159% | 0.020% | 0.036% | 0.028% | 0.046% | 0.031% | 0.027% |
| y | 1.974% | 0.128% | 0.039% | 1.008% | 0.006% | 0 | 0.020% | 3.336% | 0.708% | 3.760% | 0.035% | 0.698% | 0.900% | 1.745% | 1.043% |
| z | 0.074% | 0.326% | 1.134% | 0.467% | 0.470% | 0.494% | 1.181% | 1.500% | 0.070% | 5.640% | 1.39% | 0.034% | 0 | 0.051% | 1.599% |
| à | ~0% | 0.486% | 0 | ~0% | 0.072% | 0 | 0.635% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| â | ~0% | 0.051% | 0 | 0 | 0.562% | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| á | ~0% | 0 | 0 | 0.502% | 0.118% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 1.799% | 0 | 0.867% |
| å | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.338% | 0 | 0 | 1.190% | ~0% | 0.003% | 0 |
| ä | ~0% | 0 | 0.578% | 0 | 0 | 0 | 0 | 0 | 1.797% | 0 | 0 | 0 | 0 | 3.577% | 0 |
| ã | 0 | 0 | 0 | 0 | 0.733% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ą | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.990% | 0 | 0 | 0 | 0 | 0 |
| æ | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.872% | 0.867% | 0 | 0 |
| œ | ~0% | 0.018% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ç | ~0% | 0.085% | 0 | ~0% | 0.530% | 0 | 0 | 1.156% | 0 | 0 | 0 | 0 | ~0% | 0 | 0 |
| ĉ | 0 | 0 | 0 | 0 | 0 | 0.657% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ć | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.400% | 0 | 0 | 0 | 0 | 0 |
| č | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0.462% |
| ď | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.015% |
| ð | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 4.393% | 0 | 0 |
| è | ~0% | 0.271% | 0 | ~0% | 0 | 0 | 0.263% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| é | ~0% | 1.504% | 0 | 0.433% | 0.337% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.647% | 0 | 0.633% |
| ê | 0 | 0.218% | 0 | 0 | 0.450% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ë | ~0% | 0.008% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ę | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.110% | 0 | 0 | 0 | 0 | 0 |
| ě | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.222% |
| ĝ | 0 | 0 | 0 | 0 | 0 | 0.691% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ğ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.125% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĥ | 0 | 0 | 0 | 0 | 0 | 0.022% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| î | 0 | 0.045% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ì | 0 | 0 | 0 | 0 | 0 | 0 | (0.030%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| í | 0 | 0 | 0 | 0.725% | 0.132% | 0 | 0.030% | 0 | 0 | 0 | 0 | 0 | 1.570% | 0 | 1.643% |
| ï | ~0% | 0.005% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ı | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 5.114%* | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ĵ | 0 | 0 | 0 | 0 | 0 | 0.055% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ł | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.820% | 0 | 0 | 0 | 0 | 0 |
| ľ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% |
| ñ | ~0% | 0 | 0 | 0.311% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ń | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.200% | 0 | 0 | 0 | 0 | 0 |
| ň | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.007% |
| ò | 0 | 0 | 0 | 0 | 0 | 0 | 0.002% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ö | ~0% | 0 | 0.443% | 0 | 0 | 0 | 0 | 0.777% | 1.305% | 0 | 0 | 0 | 0.777% | 0.444% | 0 |
| ô | ~0% | 0.023% | 0 | 0 | 0.635% | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ó | 0 | 0 | 0 | 0.827% | 0.296% | 0 | ~0% | 0 | 0 | 0.850% | 0 | 0 | 0.994% | 0 | 0.024% |
| õ | 0 | 0 | 0 | 0 | 0.040% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ø | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.939% | 0 | 0 | 0 |
| ř | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.380% |
| ŝ | 0 | 0 | 0 | 0 | 0 | 0.385% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ş | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.780% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ś | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.660% | 0 | 0 | 0 | 0 | 0 |
| š | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | ~0% | 0.688% |
| ß | 0 | 0 | 0.307% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ť | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.006% |
| þ | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1.455% | 0 | 0 |
| ù | 0 | 0.058% | 0 | 0 | 0 | 0 | (0.166%) | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ú | 0 | 0 | 0 | 0.168% | 0.207% | 0 | 0.166% | 0 | 0 | 0 | 0 | 0 | 0.613% | 0 | 0.045% |
| û | ~0% | 0.060% | 0 | 0 | 0 | 0 | ~0% | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ŭ | 0 | 0 | 0 | 0 | 0 | 0.520% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ü | ~0% | 0 | 0.995% | 0.012% | 0.026% | 0 | 0 | 1.854% | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| ů | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.204% |
| ý | 0 | 0 | 0 | ~0% | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.228% | 0 | 0.995% |
| ź | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.060% | 0 | 0 | 0 | 0 | 0 |
| ż | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.830% | 0 | 0 | 0 | 0 | 0 |
| ž | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | ~0% | 0.721% |
*Siehe İ und punktloses I. ⓘ
Die folgende Abbildung zeigt die Häufigkeitsverteilung der 26 häufigsten lateinischen Buchstaben in einigen Sprachen. Alle diese Sprachen verwenden ein ähnliches Alphabet mit mehr als 25 Zeichen. ⓘ
$wgTimelinePerlCommand korrekt festgelegt ist.Auf der Grundlage dieser Tabellen ergibt sich für jede Sprache das folgende "etaoin shrdlu"-Äquivalent:
- Französisch: "esait nruol"; (indogermanisch: kursiv; traditionell wird "esartinulop" verwendet, u. a. wegen der leichteren Aussprache)
- Spanisch: "eaosr nidlt"; (indogermanisch: kursiv)
- Portugiesisch: "eaosr idmnt" (indogermanisch: kursiv)
- Italienisch: 'eaion lrtsc'; (indogermanisch: kursiv)
- Esperanto: 'eaion lsrtk' (künstliche Sprache - lexikalisch beeinflusst von indoeuropäischen Sprachen, romanisch, germanisch hauptsächlich)
- Deutsch: 'enisr atdhu'; (Indogermanisch: Germanisch)
- Schwedisch: 'eanrt sildo'; (indoeuropäisch: germanisch)
- Türkisch: "eainr lkdım"; (Türkisch)
- Niederländisch: 'enati rodsl'; (Indogermanisch)
- Polnisch: "eaioz nrwst"; (indogermanisch: baltisch-slawisch)
- Dänisch: "ernta idslo"; (Indoeuropäisch: Germanisch)
- Isländisch: "earni stulð"; (Indoeuropäisch: Germanisch)
- Finnisch: "eaint slouk"; (Uralisch: Finnisch)
- Tschechisch: 'eaoni tvsrl'; (indogermanisch: baltisch-slawisch) ⓘ
Weiterführung
Die Weiterführung der Buchstabenhäufigkeit ist die Häufigkeit von Buchstabenpaaren und -tripeln und die Worthäufigkeit sowie von Schrifteinheiten, die für eine systematische Lauteinheit stehen (Grapheme für Phoneme). Befasst man sich statt mit der geschriebenen einmal mit der gesprochenen Sprache, so kann man ganz entsprechend auch Erhebungen zur Laut- oder Phonemhäufigkeit durchführen. ⓘ
Buchstabenhäufigkeit in deutschsprachigen Texten
Aus der folgenden Tabelle lässt sich rechnerisch ableiten, dass mit den fünf häufigsten Buchstaben rund die Hälfte, und mit den zehn häufigsten Buchstaben dreiviertel der Buchstabenhäufigkeit in deutschsprachigen Texten abgedeckt ist. Die Umlaute ä, ö und ü wurden wie ae, oe und ue gezählt, ß als eigenständiges Zeichen. ⓘ
| Platz | Buchstabe | Relative Häufigkeit ⓘ |
|---|---|---|
| 1. | E | 17,40 % |
| 2. | N | 9,78 % |
| 3. | I | 7,55 % |
| 4. | S | 7,27 % |
| 5. | R | 7,00 % |
| 6. | A | 6,51 % |
| 7. | T | 6,15 % |
| 8. | D | 5,08 % |
| 9. | H | 4,76 % |
| 10. | U | 4,35 % |
| 11. | L | 3,44 % |
| 12. | C | 3,06 % |
| 13. | G | 3,01 % |
| 14. | M | 2,53 % |
| 15. | O | 2,51 % |
| 16. | B | 1,89 % |
| 17. | W | 1,89 % |
| 18. | F | 1,66 % |
| 19. | K | 1,21 % |
| 20. | Z | 1,13 % |
| 21. | P | 0,79 % |
| 22. | V | 0,67 % |
| 23. | ẞ | 0,31 % |
| 24. | J | 0,27 % |
| 25. | Y | 0,04 % |
| 26. | X | 0,03 % |
| 27. | Q | 0,02 % |
Bei einer Gleichverteilung der 27 Buchstaben betrüge die relative Häufigkeit jeweils 3,704 %. ⓘ
Zum Vergleich eine Datei, die auf 99.586 Buchstaben eines gemischten Briefkorpus einer Person (Korrespondenz mit Ämtern, Freunden, Kollegen, Rundfunkanstalten, Verlagen…; immer nur der laufende Text, also ohne Briefkopf, Anrede und Grußformel; Briefe aus den Jahren 1996–2004) beruht. Im Unterschied zur vorigen Übersicht sind die Umlautbuchstaben <ä>, <ö> und <ü> je für sich erhoben. ⓘ
| Platz | Buchstabe | Absolute Häufigkeit | Relative Häufigkeit ⓘ |
|---|---|---|---|
| 1. | E | 16.040 | 16,11 % |
| 2. | N | 10.288 | 10,33 % |
| 3. | I | 9.011 | 9,05 % |
| 4. | R | 6.693 | 6,72 % |
| 5. | T | 6.312 | 6,34 % |
| 6. | S | 6.203 | 6,23 % |
| 7. | A | 5.577 | 5,60 % |
| 8. | H | 5.177 | 5,20 % |
| 9. | D | 4.156 | 4,17 % |
| 10. | U | 3.680 | 3,70 % |
| 11. | C | 3.384 | 3,40 % |
| 12. | L | 3.226 | 3,24 % |
| 13. | G | 2.924 | 2,94 % |
| 14. | M | 2.784 | 2,80 % |
| 15. | O | 2.312 | 2,32 % |
| 16. | B | 2.176 | 2,19 % |
| 17. | F | 1.701 | 1,71 % |
| 18. | W | 1.383 | 1,39 % |
| 19. | Z | 1.351 | 1,36 % |
| 20. | K | 1.329 | 1,33 % |
| 21. | V | 912 | 0,92 % |
| 22. | P | 841 | 0,84 % |
| 23. | Ü | 636 | 0,64 % |
| 24. | Ä | 511 | 0,51 % |
| 25. | Ö | 363 | 0,36 % |
| 26. | ẞ | 189 | 0,19 % |
| 27. | J | 186 | 0,19 % |
| 28. | X | 112 | 0,11 % |
| 29. | Q | 73 | 0,07 % |
| 30. | Y | 56 | 0,06 % |
Das Institut für Deutsche Sprache in Mannheim bietet auf seinen Seiten diverse Zeichen- und Buchstabenhäufigkeitslisten zum Download an. Den Statistiken liegt eine Textstichprobe von knapp 180 Milliarden Zeichen aus dem Deutschen Referenzkorpus zugrunde (Stand 2018). ⓘ
Eine Übersicht über die Buchstabenhäufigkeit in Form eines Balkendiagramms bietet Duden auf der Grundlage des Duden-Korpus, einer Volltextsammlung mit über 2 Milliarden Wortformen; auch in dieser Übersicht werden die Umlautbuchstaben je für sich aufgelistet. Die Graphik wurde in der 27. Auflage des Rechtschreib-Duden überarbeitet, jetzt auf der Grundlage des Duden-Korpus mit inzwischen 4 Milliarden Wortformen (Stand Frühjahr 2017). ⓘ
Buchstabenhäufigkeit in ausgewählten Sprachen
| Buchstabe | Deutsch | Englisch | Französisch | Spanisch | Esperanto | Italienisch | Schwedisch | Polnisch ⓘ |
|---|---|---|---|---|---|---|---|---|
| a | 6,51 % | 8,167 % | 7,636 % | 12,53 % | 12,12 % | 11,74 % | 9,3 % | 8,0 % |
| b | 1,89 % | 1,492 % | 0,901 % | 1,42 % | 0,98 % | 0,92 % | 1,3 % | 1,3 % |
| c | 3,06 % | 2,782 % | 3,260 % | 4,68 % | 0,78 % | 4,5 % | 1,3 % | 3,8 % |
| d | 5,08 % | 4,253 % | 3,669 % | 5,86 % | 3,04 % | 3,73 % | 4,5 % | 3,0 % |
| e | 17,40 % | 12,702 % | 14,715 % | 13,68 % | 8,99 % | 11,79 % | 9,9 % | 6,9 % |
| f | 1,66 % | 2,228 % | 1,066 % | 0,69 % | 1,03 % | 0,95 % | 2,0 % | 0,1 % |
| g | 3,01 % | 2,015 % | 0,866 % | 1,01 % | 1,17 % | 1,64 % | 3,3 % | 1,0 % |
| h | 4,76 % | 6,094 % | 0,737 % | 0,70 % | 0,38 % | 1,54 % | 2,1 % | 1,0 % |
| i | 7,55 % | 6,966 % | 7,529 % | 6,25 % | 10,01 % | 11,28 % | 5,1 % | 7,0 % |
| j | 0,27 % | 0,153 % | 0,545 % | 0,44 % | 3,50 % | 0,00 % | 0,7 % | 1,9 % |
| k | 1,21 % | 0,772 % | 0,049 % | 0,00 % | 4,16 % | 0,00 % | 3,2 % | 2,7 % |
| l | 3,44 % | 4,025 % | 5,456 % | 4,97 % | 6,14 % | 6,51 % | 5,2 % | 3,1 % |
| m | 2,53 % | 2,406 % | 2,968 % | 3,15 % | 2,99 % | 2,51 % | 3,5 % | 2,4 % |
| n | 9,78 % | 6,749 % | 7,095 % | 6,71 % | 7,96 % | 6,88 % | 8,8 % | 4,7 % |
| o | 2,51 % | 7,507 % | 5,378 % | 8,68 % | 8,78 % | 9,83 % | 4,1 % | 7,1 % |
| p | 0,79 % | 1,929 % | 3,021 % | 2,51 % | 2,74 % | 3,05 % | 1,7 % | 2,4 % |
| q | 0,02 % | 0,095 % | 1,362 % | 0,88 % | 0,00 % | 0,51 % | 0,007 % | 0,00 % |
| r | 7,00 % | 5,987 % | 6,553 % | 6,87 % | 5,91 % | 6,37 % | 8,3 % | 3,5 % |
| s | 7,27 % | 6,327 % | 7,948 % | 7,98 % | 6,09 % | 4,98 % | 6,3 % | 3,8 % |
| t | 6,15 % | 9,056 % | 7,244 % | 4,63 % | 5,27 % | 5,62 % | 8,7 % | 2,4 % |
| u | 4,35 % | 2,758 % | 6,311 % | 3,93 % | 3,18 % | 3,01 % | 1,8 % | 1,8 % |
| v | 0,67 % | 0,978 % | 1,628 % | 0,90 % | 1,90 % | 2,10 % | 2,4 % | 0,00 % |
| w | 1,89 % | 2,360 % | 0,114 % | 0,02 % | 0,00 % | 0,00 % | 0,03 % | 3,6 % |
| x | 0,03 % | 0,150 % | 0,387 % | 0,22 % | 0,00 % | 0,00 % | 0,1 % | 0,00 % |
| y | 0,04 % | 1,974 % | 0,308 % | 0,90 % | 0,00 % | 0,00 % | 0,6 % | 3,2 % |
| z | 1,13 % | 0,074 % | 0,136 % | 0,52 % | 0,50 % | 0,49 % | 0,02 % | 5,1 % |
| œ | 0,00 % | 0,00 % | 0,018 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ß | 0,31 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| à | 0,00 % | 0,00 % | 0,486 % | 0,00 % | 0,00 % | siehe a | 0,00 % | 0,00 % |
| ą | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe a |
| ç | 0,00 % | 0,00 % | 0,085 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ĉ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,66 % | 0,00 % | 0,00 % | 0,00 % |
| ć | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe c |
| è | 0,00 % | 0,00 % | 0,271 % | 0,00 % | 0,00 % | siehe e | 0,00 % | 0,00 % |
| é | 0,01 % | 0,00 % | 1,904 % | 0,00 % | 0,00 % | siehe e | 0,00 % | 0,00 % |
| ê | 0,00 % | 0,00 % | 0,225 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ë | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ę | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe e |
| ĝ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,69 % | 0,00 % | 0,00 % | 0,00 % |
| ĥ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,02 % | 0,00 % | 0,00 % | 0,00 % |
| î | 0,00 % | 0,00 % | 0,045 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ì | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe i | 0,00 % | 0,00 % |
| ï | 0,00 % | 0,01 % | 0,005 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % |
| ĵ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,12 % | 0,00 % | 0,00 % | 0,00 % |
| ł | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe l |
| ń | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe n |
| ó | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe o |
| ò | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe o | 0,00 % | 0,00 % |
| ŝ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,38 % | 0,00 % | 0,00 % | 0,00 % |
| ś | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe s |
| ù | 0,00 % | 0,00 % | 0,058 % | 0,00 % | 0,00 % | siehe u | 0,00 % | 0,00 % |
| ŭ | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,52 % | 0,00 % | 0,00 % | 0,00 % |
| ź | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | siehe z |
| ż | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,00 % | 0,7 % |
Besonders bemerkenswert in der Tabelle ist, dass im Deutschen der Buchstabe E deutlich häufiger und der Buchstabe O deutlich seltener angewendet werden als in romanischen und slawischen Sprachen. ⓘ
Die Tabelle stellt nur die Häufigkeiten von Buchstaben in Texten/Korpora von Sprachen dar, für die die lateinische Schrift verwendet wird. Zur Buchstabenhäufigkeit in Sprachen mit der kyrillischen Schrift kann auf die Darstellung von Kempgen (1995) zum Russischen und die Untersuchung von Grzybek & Kehlich (2005) zum Ukrainischen verwiesen werden. ⓘ